Jonathan Sedar
Personal website and new home of The Sampler blog
Delivering Value Throughout the Analytical Process
Editor’s note: this post is from The Sampler archives in 2015. During the last 5 years a lot has changed, not least that now most companies in most sectors have contracted / employed data scientists, and built / bought / run systems and projects. Most professionals will at least have an opinion now on data science, occasionally earned.
I was prompted to dig this post up following an offline chat about a DS Project Checklist by fast.ai: it seems we all eventually stumble on thinking about the meta issues.
Let’s see how well this post has aged - feel free to comment below - and I might write a followup at some point.
The heart of data science is to use statistical and programmatic techniques to realise value from data. This applies to non-profit organisations, conventional businesses and new startups alike. That realisation can take different forms:
- For the data analyst, the outcome might be a scientific report that experiments with various techniques to discover patterns, and exhaustively applies statistical tests prove an insight
- For the software engineer, the appropriate outcome might best be an automated system (a “data product”) to repeatedly deliver analyses & predictions in future
- For the business leader, the outcome is more likely to tie directly to a strategic, organisation or operational project, creating new revenue streams, meeting compliance or reducing risk and costs
… all three viewpoints are valid and demonstrate that we all want to follow a methodical process from initial speculation, through justified strategies and hypotheses, through data analysis, to improved models, systems and processes.
Do we need a new process?
To define such a process is nothing new, and data analysis methodologies such as the Cross Industry Standard Process for Data Mining (CRISP-DM) - developed as far back as the mid-nineties - adequately capture the workflows, tasks, responsibilities, and explain the benefits to various parts of the business.
However, many aspects of data science are still maturing, the CRISP-DM process appears to be abandoned and a handful of new processes are in discussion; the most notable being OSEMN (Obtain, Scrub, Explore, Model, iNterpret).
Applied AI are often called upon to deliver analytical insights and systems where before there were none. Naturally our projects are sold upon these final deliverables, but there’s tremendous business value to be found throughout the analytical process and I think it’s worth trying to define.
A new generalised data science process: SPEACS
Every new process needs a convoluted acronym, so I’ll invent SPEACS 1. This is currently just a rough sketch, but you can see the general flow from ideas to implementation and the iterative nature.
Let’s work through each stage in more detail and discuss the value to be found.
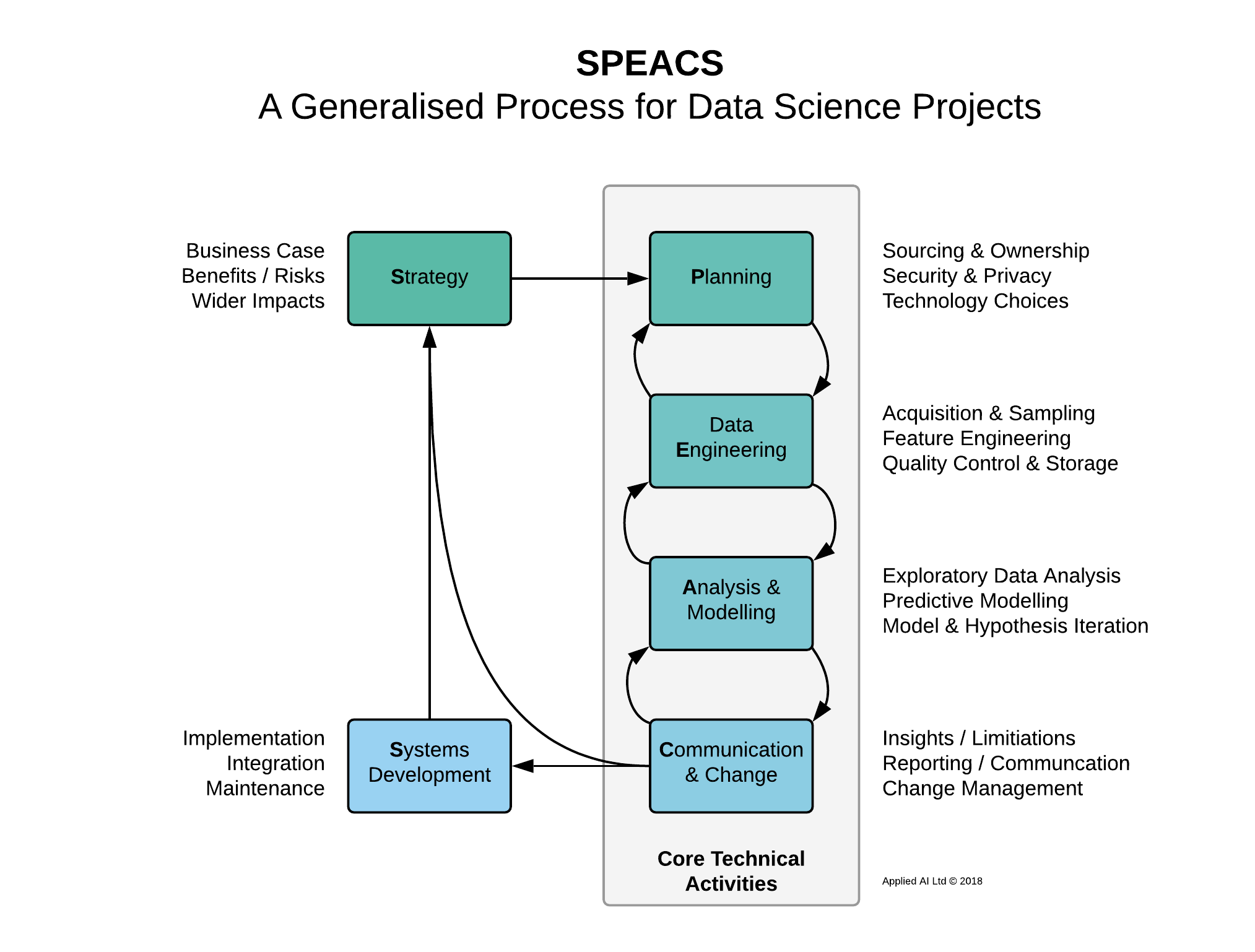
Strategy
Everything starts here: defining the business case, the potential benefits and risks. There’s many questions which we ought to try to answer before going any further, including:
Business Case
- What’s the opportunity to be seized?
- Why does it require data analysis?
- Who wants these insights and work?
- Why haven’t we done this before?
- Can we afford to do / not to do this?
- Is there a simpler way to achieve our goals?
Wider Impacts
- Who and what will be impacted by the outcome?
- What will happen if we don’t do this?
- How will this project effect the desired change in the business?
- How will we evaluate success?
On the technical side we might expect to support these questions by variously creating synthetic data, efficient data explorations & visualisation, and small simulations to deliver “what-if” analyses, make approximate estimations and help to engage with wider parts of the business.
At this stage though, we are unlikely to conduct any heavy analysis, and certainly wouldn’t implement any systems. We aim to gain valuable insights into the current & future states of the business, and build a justified case for doing performing those analyses or building those systems.
Possibly the project will stop right here, or the goals will be sought through other means, and that’s okay. Change is always hard, and every minute spent on these questions saves hours down the road.
Planning
This stage dives into the detail of what and how the project will run. I’ve placed this at the start of an iterative sub-cycle of Core Technical Activities, since planning is always tightly influenced by what’s actually possible and the various outcomes of the full process. Some considerations include:
Data Sourcing and Ownership
- What data might be useful for this analysis / product?
- How do we access and/or acquire useful data?
- Can we simulate these processes and data (anticipating the modelling stage below)?
- What does that cost us financially / operationally?
- How do we ensure data owners they are involved in the process?
- Who would own the insights derived from the data?
Addressing privacy concerns & abiding by security protocols
- Are there legal or ethical restrictions on using the data or the insights generated?
- Must the data be aggregated or anonymised prior to analysis?
- Who will have access to the data and insights?
- Must the data be encrypted in storage and transit?
- How do these decisions alter our assumptions and strategy?
Technology and process constraints
- Are there preferred technologies we should use, and why?
- How should the work integrate with other business processes and technical systems?
- Do we have the human and technical resources to embark on our plan?
At this stage we are still unlikely to have accessed any data, created descriptive analyses nor created predictive models. What we seek here is to set up the right environment (both business and technical) for the project to succeed - whilst accounting for all sorts of considerations and compromises.
The valuable outputs / artifacts / deliverables are likely to included project schedules, technical architectures, legal frameworks, privacy statements, ethical statements and priced business plans.
“An approximate answer to the right problem is worth a good deal more than an exact answer to an approximate problem.” - John Tukey 2
Data Engineering
Most analysts will tell you that data preparation consumes a disproportionate amount of project time, and they’re totally right. What you don’t hear so often is the huge amount of value created during this stage:
Data Acquisition, Storage and Quality Control
-
In the initial stages of most projects we inevitably use some data that was created for another purpose - actuarial extracts, customer transaction logs, social media and marketing messages, equity price movements etc. In fact it’s quite likely that your chosen data sources have never before been properly documented, combined and stored.
-
High quality data is documented, clean, complete and representative; it makes downstream analysis and insight generation repeatable and reliable.
-
Well maintained data sources are scalable, backed-up, always available, proximate to the data analysis, and have a data dictionary, schemas and permissions-based access.
Sampling, Feature Engineering and Tidy Data
-
Whilst ‘big data’ offers the opportunity to investigate and model a lot of information, more often than not the actual analyses can and should be performed on smaller, well-chosen sample sets. In fact, most general business issues do not involve datasets with more than a few millions of samples, which is still small data.
-
Feature engineering (the selection, creation, transformation of data) lets us consider how to cleanly and intelligently select features for use in modelling, create derivative features, and modify those that already exist.
-
Item engineering (value imputation, item exclusion, datatype modification) lets us consider how to cope with missing values and ensure that datatypes are optimal.
-
If the data itself is well-engineered - tidy data - it will often lead to new insights just by itself without statistical modelling. These are the age-old summaries, distributions and visualisations as delivered by business intelligence solutions.
Pipeline Engineering
-
We can summarise most of the above points by thinking about the data ‘pipeline’. Proper planning and engineering can make the process of data acquisition more robust, extensible, repeatable, and auditable.
-
Quality control, security, privacy and sampling can and should become more automated as a data science business function matures.
-
Many other projects throughout software development, marketing, product design, and management will all benefit from a well-maintained data pipeline.
Data Analysis & Modelling
Finally, the bit that most people think about when they hear ‘data science project’. You’ll hopefully agree though, that by this stage we should have already realised a huge amount of value for the business. Simply getting here is often be more than half of the project.
Exploratory Data Analysis and Hypothesis Testing
-
The now-standard toolkits in Python and R et al. allow us to very quickly investigate high-dimensional datasets, discover trends, visualise patterns and share insights etc. Javascript and proprietary plotting tools let us share rich, interactive visualisations with non-technical users.
-
Descriptive analysis is usually never ‘done’, and we are likely to come back to it throughout the project to investigate new data, test our ideas, and make estimates for project planning.
-
This stage really is the heart of the project cycle and you can expect to iterate through it several times. We might also stop here in the case that we answer the key business questions posed in the Strategy stage.
Predictive Modelling and Evaluation
-
It’s important to start with at least a basic hypothesis of how you expect the data to behave and what it will explain and predict
-
This hypothesis is of the data-generating process somewhere out there in the real world that resulted in the data you have acquired: that process is noisy, full of errors and assumptions, and your understanding of it may have multiple explanations that result in nearly-equivalent hypothesis (model configurations) to be argued and tested
-
Seek to prove or disprove your assumptions starting with parsimonious, explainable models of the data-generating process and always evaluate appropriately using reasoned summary statistics, prior and posterior predictions, state any asymptotic assumptions, use cross-validation and hold-out sets.
-
Prediction is often highly problem-specific and various tools & techniques are not always suitable nor are transferrable between domains. It’s important to always have a solid understanding of the actual problem to be solved, rather than blindly throwing algorithms at the data and hoping for success.
-
That said, for most practical purposes it’s reasonable to start with conventional ‘off the shelf’ algorithms that you understand and believe to approximate the data-generating process, rather than e.g. craft a bespoke Bayesian inferential model.
-
A well-tested predictive model can be immensely valuable and both the source code and trained model should be maintained, versioned and backed-up like any other software project.
“Data are not taken for museum purposes; they are taken as a basis for doing something. If nothing is to be done with the data, then there is no use in collecting any. The ultimate purpose of taking data is to provide a basis for action or a recommendation for action. The step intermediate between the collection of data and the action is prediction.” - W. Edwards Deming
Communication & Change
The final stage of this inner cycle of Core Technical Activities is communication & change: putting to use the observations and insights gained by making a change in the business or more widely. Without this stage, all the best analysis and modelling in the world is useless.
Observations and Reporting
-
Ensure that the models are answering the right question, and ensure the results are communicated in a way that is relevant, timely and accessible to the audience.
-
Good reporting is relevant reporting. Think scientifically, summarise findings to the appropriate technical or business level, ensure that results can be verified and code audited.
-
The right audience will be able to draw upon relevant observations and lead to reasoned insights.
Recommendations and Change Management
-
It’s hard to argue with well-sourced, well-supported insights, but the greatest value comes when someone makes a change - and change is hard to achieve.
-
Good stakeholder management starting from the Strategy and Planning stages ought to ensure that there is a willing audience for the above work; there’s immense value in simply bringing them along with the project.
-
Quite often, a data science project need go no further than this stage; if the analysis is sufficient to make a reasoned change, then it’s time to revisit the Strategy stage, and extend, modify or simply complete the project and move onto the next.
-
If the aim is to have a system or ‘product’, then we can move onto the next stage…
Systems
Congratulations, you’ve reached a level where it’s worthwhile to embed your insights into systems. This systemisation might be:
-
well documented scripts manually run by analysts on a regular basis
-
simple applications - potentially integrated into larger systems - providing business intelligence or predictive modelling to internal teams
-
highly technical applications more akin to a full software product, with well specified processes, user types, security, backup & failover etc etc.
Think carefully about how systems management & execution fit into regular business processes and vice versa. Implementing new technical systems is a great opportunity to redesign old business processes and make sure teams are well-configured and delivering business value.
Model Scalability, Repeatability and Responding to Experience
-
Try to keep the model complexity as low as is reasonable given the dataset and the desired results. Smaller, simpler models scale more easily and can be repeated more frequently on cheaper hardware. Generally speed of execution beats complexity.
-
It’s essential that any solutions put in place are subject to regular monitoring and re-evaluation to ensure their continued relevance. When necessary the solutions assumptions and structure may need to be updated.
Systems Development
-
Build things iteratively and keep the development process lean. Data science often looks like software development and systems implementation looks the most similar.
-
Follow an iterative process, test everything, allow for both experimentation and failure, factor in 50% more time than your most pessimistic estimates, bring stakeholders along closely with regular demos.
-
This last bit should be the easiest stage of all, since system development is very well understood by now, but it’s where we should all be very careful not to fall into the twin traps of (1) academically hand-waving away the dirty complexities & compromises of software development, and (2) the hacker’s dismissal of mathematical rigour.
-
A well-functioning data-science implementation team is of tremendous business value.
In Summary
My intention in this post was to demonstrate that a ‘data science’ project yields value all the way throughout the process, not just the analysis and modelling stages.
I’ve explained this in a new-drafted process called SPEACS, which I’ve detailed with examples and opinions gained from a several years working in the arenas of data science, consulting and systems development. I’d love to know your thoughts, and it’s likely that I’ll elaborate upon this in future.
-
Pronounced “speaks”. ↩︎
-
Tukey is always a good read. See for example his paper ‘Sunset Salvo’, in which he condenses 40+ years of observations into only a few pages of incredibly quotable and still highly-relevant insight. ↩︎